

There is a list of papers and talks from Neurlips 2020 that caught my attention more than others. I combined talks and presentations of different types like Fundamental ML Research, Applied Research, and ML applications. So this blogpost will be interesting to anyone passionate about ML.
Some links that I provided are not available if you don’t have access to the NeurIPS 2020 content. However, organizers promised that all conference content will become free to the public in late January. So links will be updated soon.
1. GAN applications in fashion article design and outfit rendering| Zalando

Zalando is performing research on neural networks to process outfits and generate new versions of outfit and new looks to improve customers’ experience. They are implementing Fashion Search by Picture that will allow users to upload pictures of the outfit they are actually looking for and find a similar product.
But what if a customer doesn’t have pictures of what they would like to buy? To solve this problem, Zalando is using GAN networks.
They are developing StyleGAN-similar-generator that allows them to create some unique/previously unseen outfits. This generator allows to upload a couple of article pictures and create a new item image by merging the styles from the examples. By doing so, customers can try different combinations until they find what they actually need.

Another big thing is the Fashion Render. This is a tool based on GANs that takes multiple articles of different classes (shoes, trousers, t-shirt) and projects them all onto a model to get pictures of the human wearing all these outfits.
Results are quite good, and the dataset that was used for this research is publicly available (STL-Dataset). So this is a good sphere for experiments and creating something new and useful.
Here are the links to the presentation from NeurIPS 2020 and the paper
2. Training Generative Adversarial Networks with Limited Data | NVIDIA

GANs highlighted by me in the previous paragraph, like many other GANs, require a lot of training data. The need for a big dataset leads to higher costs and a longer time of the experiment. To handle this problem, researchers from NVIDIA led by Terro Karras created a new approach that allows to train GANs successfully with a much lower amount of data.
Using too little data typically leads to discriminator overfitting, causing training to diverge. So the NVIDIA team proposed an adaptive discriminator augmentation mechanism that significantly stabilizes training in limited data regimes. The approach does not require changes to loss functions or network architectures, and code almost looks the same, therefore it can be used in your existing StyleGANv2 projects. It is applicable both for training from scratch and fine-tuning an existing GAN on another dataset.
Here are the links to the paper and the code
3. AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients | Yale University; University of Illinois at Urbana-Champaign; University of Central Florida
New optimizer that adapts stepsize according to the “belief” in gradient changes. Best speed and accuracy in many cases, especially for GANs.
Some details from the paper: For many models such as convolutional neural networks (CNNs), adaptive methods typically converge faster but generalize worse compared to SGD; for complex settings such as generative adversarial networks (GANs), adaptive methods are typically the default because of their stability. We propose AdaBelief to simultaneously achieve three goals: fast convergence as in adaptive methods, good generalization as in SGD, and training stability. The intuition for AdaBelief is to adapt the stepsize according to the “belief” in the current gradient direction. Viewing the exponential moving average (EMA) of the noisy gradient as the prediction of the gradient at the next time step, if the observed gradient greatly deviates from the prediction, we distrust the current observation and take a small step; if the observed gradient is close to the prediction, we trust it and take a large step. We validate AdaBelief in extensive experiments, showing that it outperforms other methods with fast convergence and high accuracy on image classification and language modeling. Specifically, on ImageNet, AdaBelief achieves comparable accuracy to SGD. Furthermore, in the training of a GAN on Cifar10, AdaBelief demonstrates high stability and improves the quality of generated samples compared to a well-tuned Adam optimizer.
Here are the links to the paper and the code
4. RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder | Institute of Automation, CAS and Microsoft Research Asia
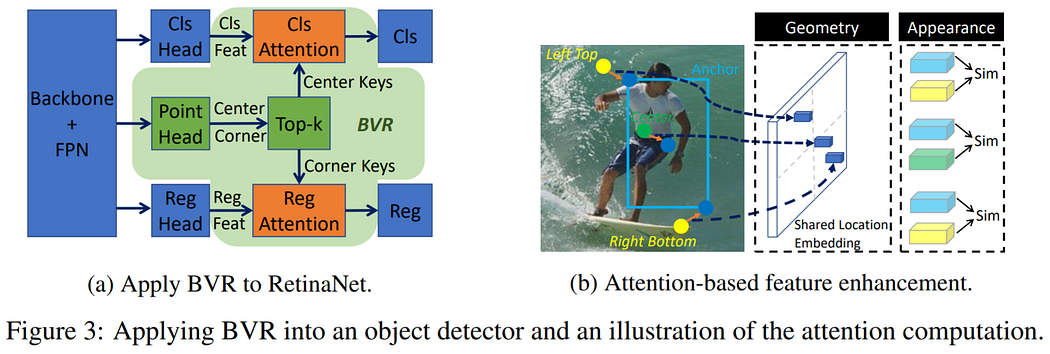
Mask-RCNN is the neural network with a multi-staged design, and it is performing a refinement of detections/masks/predictions in multiple steps. Multiple steps of refinement, as a result, gives higher accuracy in comparison with one-staged solutions (Yolo, SSD, and others).
Creators of the RelationNet++ approach found a way to add Transformer NN to the end of any detection models (Faster-RCNN/RetinaNet/FCOS/CornerNET). This Transformer block acts somehow like a refinement module that gives higher accuracy to any detection neural networks.
Here is the link to the paper
5. A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection | Dept. of Computer Engineering, Middle East Technical University Ankara, Turkey

Localisation-Recall-Precision (aLRP) is a unified, bounded, balanced, and ranking-based loss function for both classification and localization tasks in object detection. aLRP extends the Localisation-Recall-Precision (LRP) performance metric inspired from how Average Precision (AP) Loss extends precision to a ranking-based loss function for classification. aLRP has the following distinct advantages: (i) aLRP is the ranking-based loss function for both classification and localization tasks. (ii) aLRP naturally enforces high-quality localization for high-precision classification. (iii) aLRP provides a provable balance between positives and negatives. (iv) Compared to, on average ∼6 hyperparameters in the loss functions of state-of-the-art detectors, aLRP Loss has only one hyperparameter, which we did not tune in practice. On the COCO dataset, aLRP Loss improves its ranking-based predecessor, AP Loss, up to around 5 AP points, achieves 48.9 AP without test time augmentation, and outperforms all one-stage detectors.
Here are the links to the paper and the code
6. Automatic generation of movie thumbnails and trailers|Machine Learning at NETFLIX

NETFLIX team created several Neural Networks and algorithms for automatic thumbnails generation and ArtWork generation from videos. Algorithms include Character Recognition, Object Detection, Face Recognition, Scene Understanding, Aesthetic analysis. Having multiple thumbnails for each TVShow/Movie allows them to show a personalized version of it for each customer and maximize audience interest.
This is how pipeline goes: NETFLIX scans through the movie, detects faces and facial expressions, and analyzes aesthetics of each frame. After that, they create a connected graph of the characters that allows them to grasp the movie's main characters (the most frequently connected persons are the main heroes) and select the best frames that contain these characters. Link on the presentation
They also use a certain set of algorithms to automatically select movie episodes applicable for generation movie trailers.
Here is the link to the paper
Get Denis Timonin’s stories in your inbox
Join Medium for free to get updates from this writer.
Subscribe
7. Slate Bandit Learning & Evaluation|Machine Learning at NETFLIX

NETFLIX’s talk is about applying Reinforcement Learning and Bandits to the marketing problem of the designing email interfaces. This approach can be applied to any other tasks when some application has UI (User Interface) slots that need to be filled in with different buttons or functional regions that require actions from users.
Using different Reinforcement Learning techniques, we can find an optimal combination of the UI elements for clusters of the users to maximize their engagement.
NETFLIX described one of their tasks of such type and proposed a solution for it.
Here is the link to the talk
8. Autoencoders for Recommender Systems | Machine Learning at NETFLIX
Recommender systems are one of the core technologies in NETFLIX. Autoencoders may be one of the tools that allow to catch important features from the user’s behavior and to use them for recommendations. NETFLIX described how they changed the training pipeline to force autoencoders to act in an Attention-style manner in their talk. They dropped some input data features in training time to force autoencoder to predict dropped features based on their neighbors. This technique + new regularization improved accuracy of their RecSys.
Here is the link to the paper
9. Reference-Based Video Colorization with Spatiotemporal Correspondence | SONY Research

SONY proposed a novel reference-based video colorization framework with spatiotemporal correspondence. Reference-based methods colorize grayscale frames referencing a user input color frame. Previously released methods suffer from the color leakage between objects and the emergence of average colors, derived from non-local semantic correspondence in space. To address this issue, SONY warp colors only from the regions on the reference frame restricted by correspondence in time. They propagate masks as temporal correspondences, using two complementary tracking approaches: off-the-shelf instance tracking for high-performance segmentation and newly proposed dense tracking to track various types of objects.
As a result, their approach propagates faithful colors throughout the video and outperforms state-of-the-art methods quantitatively and qualitatively.
Here is the link to the paper
10. Learning to Detect Objects with a 1 Megapixel Event Camera | PROPHESEE and NNAISENSE

Event cameras encode visual information with high temporal precision, low datarate, and high-dynamic range. Thanks to these characteristics, event cameras are particularly suited for scenarios with high motion, challenging lighting conditions, and requiring low latency. However, due to the novelty of the field, the performance of event-based systems on many vision tasks is still lower compared to conventional frame-based solutions. The main reasons for this performance gap are the lower spatial resolution of event sensors compared to frame cameras; the lack of largescale training datasets; the absence of well established deep learning architectures for event-based processing. In this paper, researchers addressed all these problems in the context of an event-based object detection task. First, they publicly released the first high-resolution large-scale dataset for object detection. The dataset contains more than 14 hours recordings of a 1 megapixel event camera, in automotive scenarios, together with 25M bounding boxes of cars, pedestrians, and two-wheelers, labeled at high frequency. Second, they introduced a novel recurrent architecture for eventbased detection and a temporal consistency loss for better-behaved training. The ability to compactly represent the sequence of events into the internal memory of the model is essential to achieve high accuracy. Their model outperforms by a large margin feed-forward event-based architectures.
Here is the link to the paper
11. Kernel Based Progressive Distillation for Adder Neural Networks | HUAWEI and others
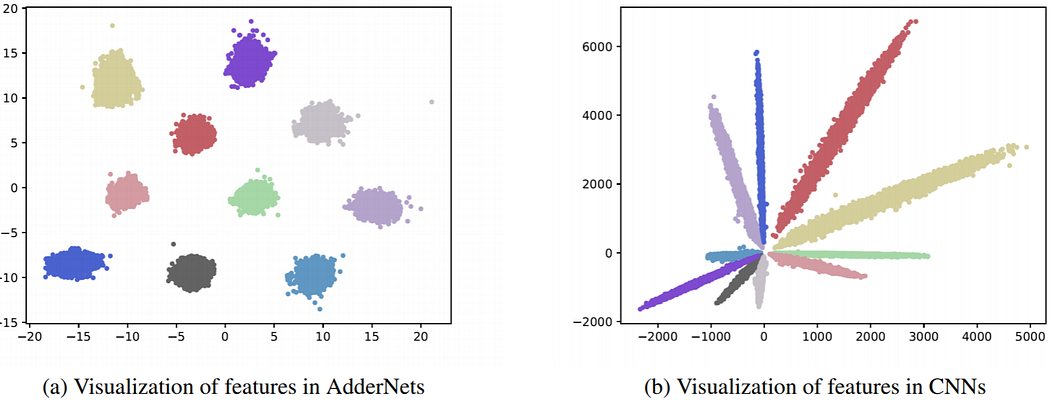
This is the series of 2 papers:
In the first paper (AdderNet: Do We Really Need Multiplications in Deep Learning?) presented on CVPR 2020, researchers proposed to replace cross-correlation (multiplications) with l1-distance (additions)in convolution layers. And to achieve a better performance, they develop a special back-propagation approach for AdderNets by investigating the full-precision gradient. As a result, the proposed AdderNets can achieve 74.9% Top-1 accuracy 91.7% Top-5 accuracy using ResNet-50 on the ImageNet dataset without any multiplication in convolution layer.
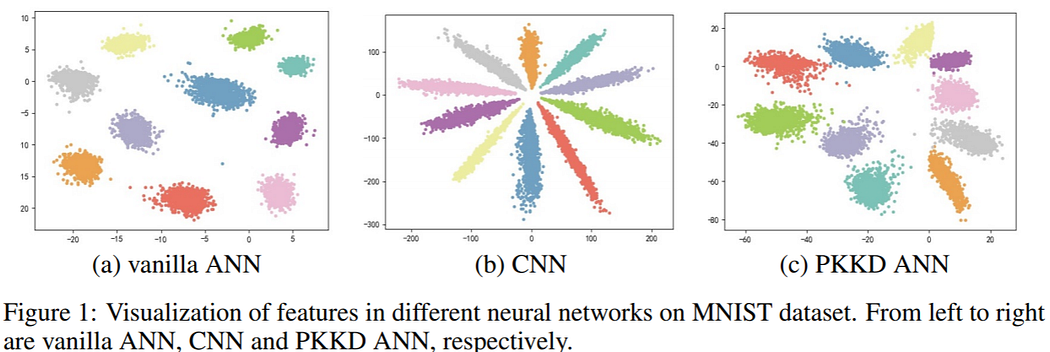
The second paper (Kernel Based Progressive Distillation for Adder Neural Networks) was presented on NeurIPS 2020. In this paper, researchers improved training pipeline to reduce accuracy drop in AdderNets. The main idea is: “If backprop through L1 gives us some inaccurate results, let’s train 2 similar neural networks together, but one of them will be regular Conv NN. We distill some useful characteristics from Conv filters into Addr filters”. A convolutional neural network (CNN) with the same architecture is simultaneously initialized and trained as a teacher network. Features and weights of ANN and CNN will be transformed into a new space to eliminate the accuracy drop. This technique is quite complex in training, but it works, and accuracy drop disappeared.
12. Compositional Explanations of Neurons | Stanford

A fascinating paper from the domain of explainability of Neural Networks.
The main task of the paper is to explain what neurons have learned in human-understandable terms.
Neurons are not just simple feature detectors, but razer operationalize complex decision rules composed of multiple concepts. Each neuron can fire on multiple image/NLP domains and features.
Researchers given a set of inputs (a) and scalar neuron activations (b) converted into binary masks (c), generate an explanation via beam search, starting with an inventory of primitive concepts (d), then incrementally building up more complex logical forms (e). They attempt to maximize the IoU score of an explanation (f); depicted is the IoU of M483(x) and (water OR river) AND NOT blue.
Here is the link to the paper
13. Shared Interest: Human Annotations vs. AI Saliency | MIT
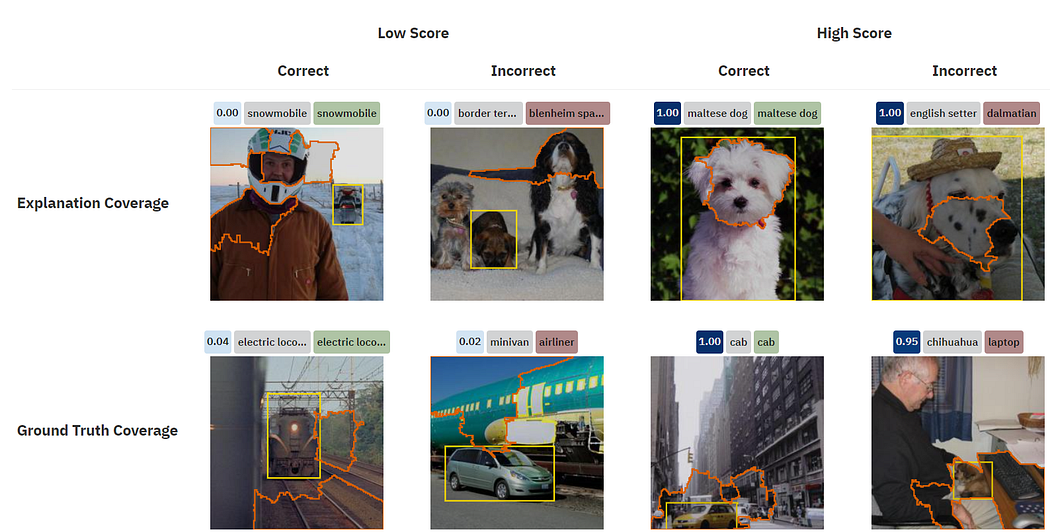
Researchers from MIT developed a tool that helps understand how our detection/segmentation models make their predictions and where mistakes come from. It compares mIoU between segmentation masks/bboxes and saliency maps of the model (LIME technique was used in example) to sort cases where the model looks in the wrong direction. Having understood that, we can think about how our dataset needs to be changed, expanded, or augmented.
Here is the link to the paper and the code
14. RetaiL: Open your own grocery store to reduce waste | Universiteit van Amsterdam
OpenAI’s Gym is a quite popular toolkit for developing and comparing reinforcement learning algorithms. While OpenAI’s gym is focused on games out-of-the-box, researchers from the University of Amsterdam created a new toolkit that simulates the grocery store.
Food waste is a major societal, environmental, and financial problem. One of the main actors are grocery stores. This is why the authors propose RetaiL, a new simulation framework (like the gym), to optimize grocery store restocking for waste reduction. RetaiL offers its users the possibility to create synthetic product data, based on real data from a European retailer. It then matches simulated customer demand to a restocking policy for those items, and evaluates a utility function based on generated waste, item availability to customers and sales. This allows RetaiL to function as a new Reinforcement Learning Task, where the agent has to act on restocking level given the state of the store, and receives this utility function as a reward.
Here is the link to the code
15. tspDB: Time Series Predict DB | MIT
An important goal in Systems for ML is to make ML broadly accessible. Arguably, the major bottleneck is not the lack of access to prediction algorithms. Rather, it is the complex data engineering required to take data from a datastore or database (DB) into a particular work environment format (e.g. spark data-frame) so that a prediction algorithm can be trained.
Towards easing this bottleneck, researchers presented tspDB — a system that enables predictive query functionality in any existing time-series relational DB (open-source available at tspDB.mit.edu). Specifically, tspDB enables two types of predictive queries for time series data: (i) imputing a missing/noisy observation for a data point we do observe; (ii) forecasting a data point in the future. In tspDB the ML workflow is entirely abstracted away from the user; instead a single interface to answer both a predictive query and a standard SQL SELECT query is exposed. Creators said that tspDB statistically outperforms industry standard deep-learning-based time series methods (e.g., DeepAR, LSTM’s) on benchmark time series datasets;
Here are the links to the project and the colab notebook